This is the first post in the Laser category. I wrote “Structural Beam Bending” because I am not referring to a laser beam, but an aluminum beam in my laser.
It took me a while to get back on the engineering concepts train. The last time I did any unit conversions at all was at least 5 years ago.
The first major hiccup I experienced while attempting to do beam bending calculations with a program called BeamBoy was that I wanted to determine my beam lengths in inches. All of my material data is in metric, so converting mm4 to in4 took me a moment to realize you simply divide by (mm/inch)^4, which is 25.4^4, or 416,231.4256
Unlike programming, physics information is not as readily available in easily digestible formats. I will outline my experiences to help anybody else who stumbles across this blog.
To calculate beam deflection:
Find your material’s Moment of Inertia, Modulus of Elasticity, and the Distance to Farthest Fiber.
My parts come from Misumi, so their data sheet looks like this: 
The Moment of Inertia for the two axes are clearly shown. The Modulus of Elasticity is a property of the material, and I couldn’t actually find the exact grade of aluminum Misumi is using, so I looked online for average values and it ranged from 9,000,000 PSI to 11,000,000 PSI.
Distance to farthest fiber is the farthest distance from the beam’s neutral axis, so I interpret that to be 1/2 the width. This may be wrong.
First, start up BeamBoy and type in the length of your beam.
Enter in the properties of your beam as discussed above: moment of inertia, modulus of elasticity, and distance to farthest fiber.
Next, add two supports to your structure, I simply added a support at the start and end of my beam.
Add a distributed load over the length of your beam equal to the weight per distance (in my case, lb/ft) to simulate the weight of the beam itself.
Optionally, add a distributed or point load to the beam. I wanted maximum deflection for a given weight so I used a point load in the “worst” possible spot: the center, away from my 2 support structures.
Click calculate and see your results!

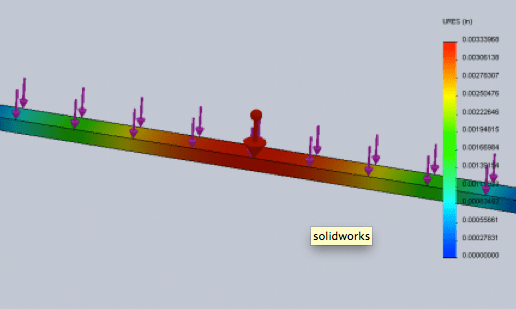
PS: I tried doing this in Solidworks beam modeler but the results don’t seem to be accurate.. Perhaps it’s because I was using a distributed load?
The Solidworks beam simulation is potentially a huge time saver as you the length, material properties and thickness is auto calculated.
Just can’t trust it yet.