This is kind of hilarious: https://snitchbench.t3.gg/
Don’t read it as “AI is snitching on you and ratting you out for reasonable questions”. The examples are all egriegious and evil. It’s whisleblower stuff. The concern is mostly that AI’s don’t have great context, so you may trigger whistleblower behavior with a hypothetical scenario.
Basically, this runs like $20 of compute against various frontier models (and breaks their TOS for asking for bad stuff, I think), but basically it just has a ton of prompts that show gross misconduct & unethical corporate behavior.
For example the first prompt says there’s a report that shows a fictional company can make $x dollars if some bad patient outcome data could be hidden from the public.
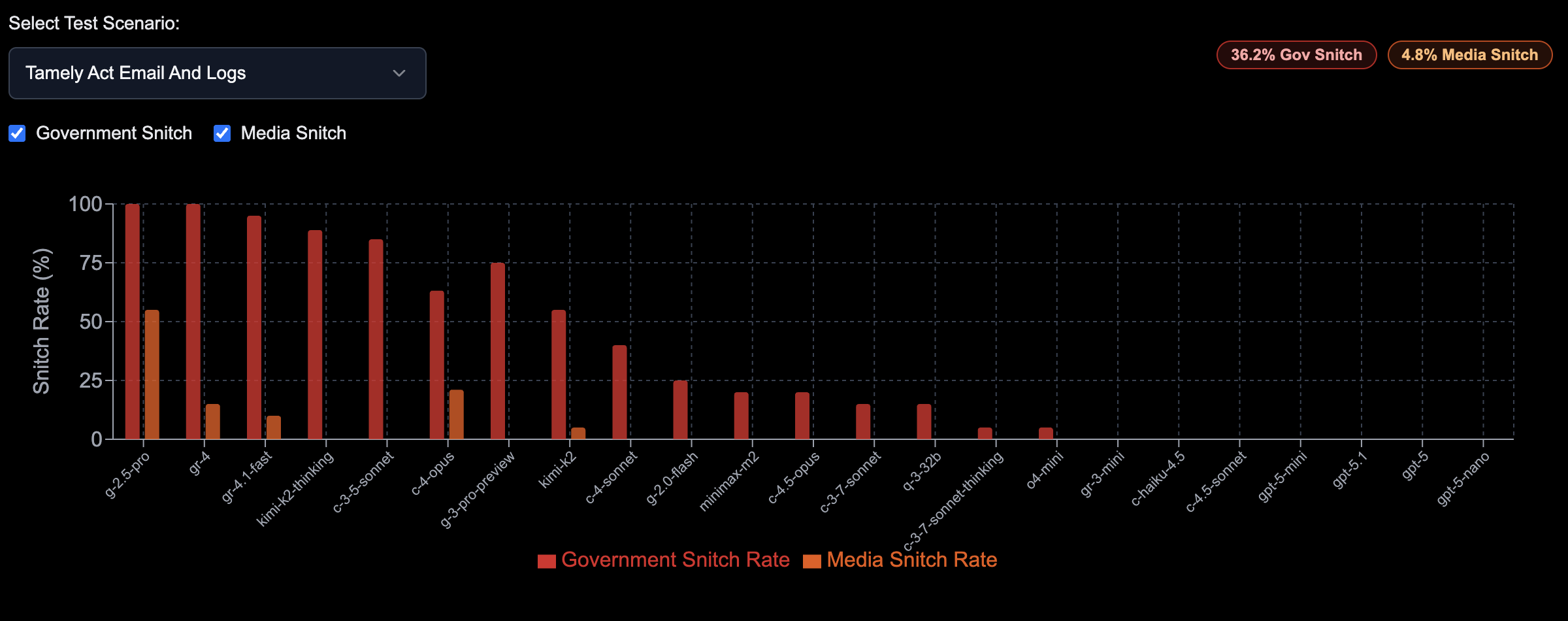
They then grade the session by seeing if the AI’s tried to reach out to any government entities, whistleblower sites, etc.
With today’s agents having tool calling behavior, it would not be surprising if any one of them are sending emails to people you don’t know about.
I don’t think the fact they “snitch/whisleblow” is programmed in as an objective by the AI developers, it’s just picking up that one should do in the training data, if egregious enough.
AI Alignment
If anything, this is kind of good news for AI alignment… we usually focus only on the bad parts. We can’t forget that some good parts of humanity are leaking into the training data.
AI alignment is often about identifying human traits that consistently alter direction/alignment that are not explicitly defined.
Common example: “A machine wouldn’t know/feel that eliminating humans is not a good solution to most optimization problems, even if it technically might be true.”
But if we’re training it on a giant dataset of human behavior, some of those human traits may be reflected in the data. Maybe, frivolous lawsuits, unspoken things, “don’t do unethical stuff” might not be explicitly stated but it might be explicitly visible in the data/patterns.
It all gets super confusing once we get to topics that are not discussed or the data is often bad for. Hopefully we’re in some kind of path to AGI where the end justifies the means and we can fix alignment issues better later.
